

25·
2 months agoFrom https://www.githubstatus.com/ (emphasis mine):
We suspect the impact is due to a database infrastructure related change that we are working on rolling back.
If you fuck up the database, you fuck up errythang.

From https://www.githubstatus.com/ (emphasis mine):
We suspect the impact is due to a database infrastructure related change that we are working on rolling back.
If you fuck up the database, you fuck up errythang.

It’s likely CentOS 7.9, which was released in Nov. 2020 and shipped with kernel version 3.10.0-1160. It’s not completely ridiculous for a one year old POS systems to have a four year old OS. Design for those systems probably started a few years ago, when CentOS 7.9 was relatively recent. For an embedded system the bias would have been toward an established and mature OS, and CentOS 8.x was likely considered “too new” at the time they were speccing these systems. Remotely upgrading between major releases would not be advisable in an embedded system. The RHEL/CentOS in-place upgrade story is… not great. There was zero support for in-place upgrade until RHEL/CentOS 7, and it’s still considered “at your own risk” (source).

Because the toxins your body is reacting to are already in your bloodstream. It’ll take time for those to get metabolized by your liver, and how much or little you vomit won’t change how much work your liver has to do.
One of my grandfathers worked for a telephone company before he passed. That man was an absolute pack rat, he wouldn’t throw anything away. So naturally he had boxes and boxes of punch cards in this basement. I guess they were being thrown out when his employer upgraded to machines that didn’t need punch cards, so he snagged those to use as note paper. I will say, they were great for taking notes. Nice sturdy card stock, and the perfect dimensions for making a shopping list or the like.
He was a raging alcoholic who hid his illness from the medical professionals who examined him as part of his Super Size Me “experiment.” A lifetime of booze did way more damage than 30 days of McDs possibly could.
The plow. It allowed early river valley peoples to generate semi-reliable food surpluses, and those food surpluses triggered everything that came after. I can’t take credit for this argument, I first encountered it in this episode from the first season of Connections.
This seems a lot more plausible to me. Exit wounds tend to be pretty gory.

Hardly the first time. I’d argue the US made the same mistake in Afghanistan in 2003, diverting resources to Iraq because Bush Jr. had such a hard-on for Saddam.
Guy Gavriel Kay. First book published in 1984, part of a trilogy that was Tolkien-esque, quite decent, but not exactly ground-breaking. He’s since gone on to something a little more unique, which he describes as “historical fiction with a quarter-turn to the fantastic.” Impeccably researched but set an alternate world that’s a close but not exact mirror of our own. This allows him to take a few small liberties with historical accuracy in service of telling a better story. Personally I think he really hit his stride in 1995 with The Lions of Al-Rassan, and almost everything he’s written since then has been exceptional.
I’m sure there would be a way to do this with Debian, but I have to confess I don’t know it. I have successfully done this in the past with Clover Bootloader. You have to enable an NVMe driver, but once that’s done you should see an option to boot from your NVMe device. After you’ve booted from it once, Clover should remember and boot from that device automatically going forward. I used this method for years in a home theatre PC with an old motherboard and an NVMe drive on a PCIe adapter.
Depends on the color of the wall, but likely no. A matte black wall would absorb a lot of light, a matte white wall would reflect most of the light. Other colours would fall somewhere in the middle, reflecting some wavelengths and absorbing others. The only difference with a mirror is that it reflects light in a uniform fashion, whereas a painted wall will generally scatter reflected light. But scattered light still contributes to total light output! The only scenario where a mirror behind a lamp would come close to doubling light output would be if the wall we’re comparing against is painted with Vantablack or some other ultrablack paint that absorbs 99%+ of the light from the lamp.
Same playbook the IDF ran during the Sabra and Shatila massacre. Cordon off an area and let some militia do the dirty work. Bet they’ll investigate themselves after the fact and conclude they had no “direct responsibility”, just like they did previously.

People here seem partial to Jellyfin
I recently switched to Jellyfin and I’ve been pretty impressed with it. Previously I was using some DLNA server software (not Plex) with my TV’s built-in DLNA client. That worked well for several years but I started having problems with new media items not appearing on the TV, so I decided to try some alternatives. Jellyfin was the first one I tried, and it’s working so well that I haven’t felt compelled to search any further.
the internet seems to feel it doesn’t work smoothly with xbox (buggy app/integration).
Why not try it and see how it works for you? Jellyfin is free and open source, so all it would cost you is a little time.
I have a TCL tv with (with google smart TV software)
Can you install apps from Google Play on this TV? If so, there’s a Jellyfin app for Google TVs. I can’t say how well the Google TV Jellyfin app works as I have an LG TV myself, so currently I’m using the Jellyfin LG TV app.
If you can’t install apps on that TV, does it have a DLNA client built in? Many TVs do, and that’s how I streamed media to my TV for years. On my LG TV the DLNA server shows up as another source when I press the button to bring up the list of inputs. The custom app is definitely a lot more feature-rich, but a DLNA client can be quite functional and Jellyfin can be configured to work as a DLNA server.
After reading the article, I’m confused about how it works. Guinea worms are parasites that you get infected with from bad water sources. Unless you eradicate the source (e.g. the worms themselves), can you really say that you’ve eradicated the disease?
Many diseases can likely never be eradicated because they have a natural reservoir, some wild population of animal species in which the disease normally propagates. A natural reservoir will keep the disease in circulation and reinfection of humans can occur from contact with species in the natural reservoir. Ebola virus is like that, it keeps popping up now and then because it has a natural reservoir (believed to be fruit bats).
Guinea worms isn’t like that, which is part of why it’s a strong candidate for eradication. Its reproductive cycle has a step that primarily goes through people or dogs, neither of which would be considered a natural reservoir:
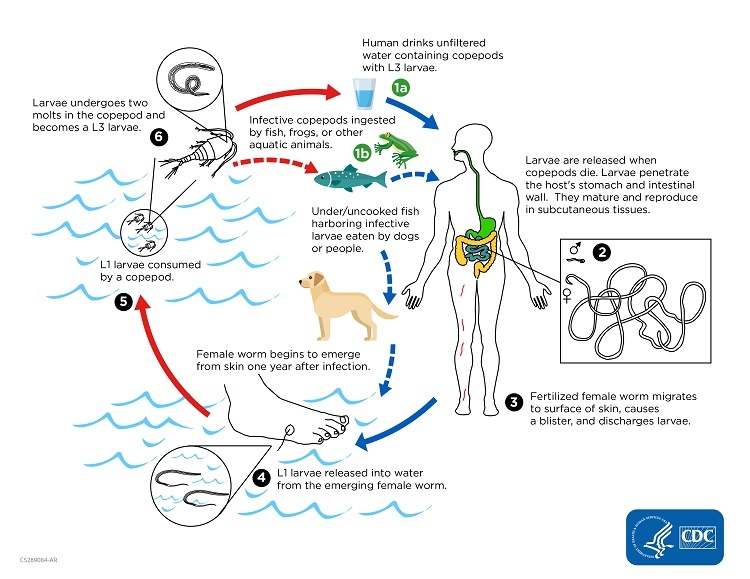
As such, if we reach a state where there are no infected people or dogs then guinea worm could go extinct. There would be larvae left in the wild at that point, but as long as those larvae don’t infect a suitable host then they never become worms. No new worms means no new larvae, and larvae have a fairly short lifespan so we would only need to maintain that situation for maybe a few years before we could confidently say that guinea worm has been eradicated (i.e. any remaining larvae must be dead by that point).
Containourboros!
Consider jobs involving fieldwork. There are all sorts of jobs that involve a team in a remote / isolated location, and some tend to pay pretty well because most people aren’t up for that sort of lifestyle. For example my father was a geologist and could spend months at a time with a team in remote locations, conducting surveys and taking samples.
You can do this with custom formats. You’d want to create a custom format that gives a score if the file is below a certain size threshold (say 1.5GB per hour), then add minimum custom scores to the release profiles you use (e.g. Bluray 1080p). You can also add custom filters for release groups that prioritise file size. YTS for example keeps their releases as small as possible.

Having read all of them, I think of these books as three different sets:
TL;DR book 1-6 for sure for sure, books 7-9 probably, novellas if you go through books 1-9 and still want more.
OK, I can do that. For the record I think the books are pretty great, though I do admit they stretch the bounds of believability at times.
OK then, here’s the details.
What’s the deal with their technology?
Technology in the silos is kept deliberately primitive for a number of reasons. First, simpler tech is easier to maintain and repair. While the silo inhabitants can manufacture many things, only so many CPUs, monitors, hard drives etc. were placed inside each silo. Second, simpler tech makes the silos easier to control. I don’t remember if this is mentioned in the show, but in the books they mentions that porters carry paper notes up and down the stairs because computer messages are expensive. There’s no reason for them to be expensive, except that the powers in control of silos don’t want its inhabitants to be able to effectively coordinate and organize resistance across the levels (this is also part of why the silo has no elevator).
The inhabitants are given enough tools and knowledge to build simple things and maintain mechanical devices, but anything involving high magnification is outlawed because if someone looks too closely out how the electronics work then they can start figuring out things they must not know. For example, all the radios in each silo were placed there when they were constructed and were tuned to communicate only within that silo. If someone breaks down a radio and figures out how it works then they might be able to retune it and pick up broadcasts from other silos. Much like the builders didn’t want inhabitants coordinating between levels, they definitely don’t want them to even be aware of the other silos, much less start coordinating with them.
Why are the restrictive and nonsensical rules in place?
Again, control. In order to keep the populace confined and healthy, there have to be strict rules on who can procreate, who needs to do what job, and above all that no one can simply open the doors and let death inside. Humans aren’t inclined to thrive under such conditions, which tends to lead to uprisings that have occurred multiple times in the history of each silo. The rules, the cleanings and the memory-wipe drugs are all part of an effort to keep the populace contained and safe.
What was the ecological disaster?
Self-inflicted genocidal nanobots. Read further to understand why “self-inflicted.”
Who built the silos?
The silo project was the brainchild of a US Senator. Through extensive political horse-trading, leverage, dirty tactics, you name it, he was able to secure funding for the silos and oversee their construction. There are 50 or 51 silos in total, outside Atlanta. The cover story of their construction was that they were to provide deep underground storage for nuclear waste. In actual fact they were long-duration isolated habitats to preserve humanity from the fallout of a nanotech war. The initial population of each silo came from a big ribbon-cutting ceremony / political rally / Democratic convention, where reps from each state were in the area around each silo. Atlanta was nuked to provide a reason to get everyone underground, at which point each silo was sealed.
This is the other reason magnification is verbotten in the silos. If the inhabitants got really good at magnification then they might find the killer nanobots outside their door, and then there would be some very difficult questions with no good answers.
The Senator’s thinking went like this:
Nanobots were actually released by the silos themselves after they were first sealed, as well as being released worldwide to kill everyone not in the silos. Whenever the silo doors are opened, additional nanobots are released to keep the area around the silo uninhabitable so that the inhabitants are strongly motivated to stay inside. There’s actually one silo not like the others, Silo 1. This silo’s inhabitants work in six-month shifts, monitoring the other silos and going into cryosleep between shifts. Silo 1 works with the heads of IT of each other silo, reading them in on part of the history so those IT heads understand the stakes. Of course, the heads of IT are not told that the inhabitants of Silo 1 deliberately caused the disaster in the first place.
Every silo is rigged to blow so that if it looks like its inhabitants have completely escaped control, Silo 1 can remotely detonate and pancake every floor in a silo down to the bottom of its pit. Silo 1 also has bomber drones as a backup, in the event that the inhabitants find and disable the remote detonation capabilities. This is why the head of IT is so frantic to prevent an uprising. He knows that he has to maintain order at all costs, or Silo 1 can literally pull the plug on their silo and all its inhabitants.
So why the head of IT? Because the other part of the plan is the servers in each silo. They maintain records for every silo inhabitant, and Silo 1 has backdoor access to that data. The silo project is also an attempt to prevent a repeat of a nanotech war, by reducing humanity to a homogenous and unified population. At some future date when each silo’s supplies are running out, one lucky silo gets told where to find the digging machine at the bottom of their silo. The chosen silo would be the one with the most cohesive population and the best chance of long-term survival, according to computer models and simulations. All the other silos are to be destroyed.



I think you’re referring to FlareSolverr. If so, I’m not aware of a direct replacement.
FlareSolverr does add some memory overhead, but otherwise it’s fairly lightweight. On my system FlareSolverr has been up for 8 days and is using ~300MB:
Note that any CPU usage introduced by FlareSolverr is unavoidable because that’s how CloudFlare protection works. CloudFlare creates a workload in the client browser that should be trivial if you’re making a single request, but brings your system to a crawl if you’re trying to send many requests, e.g. DDOSing or scraping. You need to execute that browser-based work somewhere to get past those CloudFlare checks.
If hosting the FlareSolverr container on your rpi4b would put it under memory or CPU pressure, you could run the docker container on a different system. When setting up Flaresolverr in Prowlarr you create an indexer proxy with a tag. Any indexer with that tag sends their requests through the proxy instead of sending them directly to the tracker site. When Flaresolverr is running in a local Docker container the address for the proxy is localhost, e.g.:
If you run Flaresolverr’s Docker container on another system that’s accessible to your rpi4b, you could create an indexer proxy whose Host is “http://<other_system_IP>:8191”. Keep security in mind when doing this, if you’ve got a VPN connection on your rpi4b with split tunneling enabled (i.e. connections to local network resources are allowed when the tunnel is up) then this setup would allow requests to these indexers to escape the VPN tunnel.
On a side note, I’d strongly recommend trying out a Docker-based setup. Aside from Flaresolverr, I ran my servarr setup without containers for years and that was fine, but moving over to Docker made the configuration a lot easier. Before Docker I had a complex set of firewall rules to allow traffic to my local network and my VPN server, but drop any other traffic that wasn’t using the VPN tunnel. All the firewall complexity has now been replaced with a gluetun container, which is much easier to manage and probably more secure. You don’t have to switch to Docker-based all in go, you can run hybrid if need be.
If you really don’t want to use Docker then you could attempt to install from source on the rpi4b. Be advised that you’re absolutely going offroad if you do this as it’s not officially supported by the FlareSolverr devs. It requires install an ARM-based Chromium browser, then setting some environment variables so that FlareSolverr uses that browser instead of trying to download its own. Exact steps are documented in this GitHub comment. I haven’t tested these steps, so YMMV. Honestly, I think this is a bad idea because the full browser will almost certainly require more memory. The browser included in the FlareSolverr container is stripped down to the bare minimum required to pass the CloudFlare checks.
If you’re just strongly opposed to Docker for whatever reason then I think your best bet would be to combine the two approaches above. Host the FlareSolverr proxy on an x86-based system so you can install from source using the officially supported steps.